MySQL 基础使用
数据表操作
load data infile '加载数据文件路径' into table 表名- 将文件数据加载到表中
数据查询操作
注意:
- 进行部分字符匹配应该使用
regexp或者not regexp,^$表示字符串开始或结束位置,{n}表示匹配n次 - 在select可以定义变量,以
@开头,以:=赋值,例:select @max_1:=Max(price), @min_1:=Min(price) from order - 过滤重复数据可以使用
bit_count+bit_or或者distinctbit_count是计算二进制中包含1的个数,bit_or是对两个二进制数进行或运算select year, month, bit_count(bit_or(1<<day)) as days from date_table order by year, month;- 以年和月来分组,查询日期的天数(对日期进行了去重)select distinct 字段名 from 表名;- 用distinct去重
auto_increment可以使字段值字段递增,alter table 表名 auto_increment=值可以手动调整增长的开始值
多表查询
交叉连接
select * from 表1名, 表2名;select * from 表1名 cross join 表2名;- 交叉连接是对两个表执行笛卡尔积,返回两个表行数据对所有组合,生成表大小为 表1行数 * 表2行数
内连接
SELECT * FROM <左表> INNER JOIN <右表> ON <条件>;SELECT * FROM <左表>,<右表> WHERE <条件>;- 内连接是先产生笛卡尔积,然后对数据进行过滤,只保留满足条件的数据行
- 在只有连个表的时候,最好使用
on进行内连接,会先进行筛选在连接,更高效
外连接
- 外连接分为左外连接和右外连接
SELECT * FROM <左表> LEFT JOIN <右表> ON <左表>.<字段名> = <右表>.<字段名>;SELECT * FROM <左表> RIGHT JOIN <右表> ON <左表>.<字段名> = <右表>.<字段名>;- 左外连接表示无论右表是否能匹配,都保留左表的数据
- 右外连接表示无论左表是否能匹配,都保留右表的数据
- MySQL中没有全连接,全连接就是交叉连接
联合查询
- 两个表要查询的字段一样,就可以使用联合查询用一个表展示结果
SELECT <字段名> FROM <表名> UNION SELECT <字段名> FROM <表名>;- 联合查询可以使用关键字
union或者union all,区别在于union会去除重复数据
子查询
自查询就是在查询中嵌套查询,自查询可以使用 IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS 等关键字,如果自查询结果只有一个值,还可以使用比较运算符来连接子查询,
TODO in exists any all 的区别
约束和索引
约束
show create table 表名 - 可以查看哪些表中约束的详情
主键约束 primary key
create table 表名 (字段名 字段类型 primary key);alter table 表名 modify 字段名 字段类型 primary key;alter table 表名 drop primary key;- 添加数据时主键字段不能为null
唯一约束
create table 表名 (字段名 字段类型 unique);alter table 表名 modify 字段名 字段类型 unique;alter table 表名 drop index 字段名- 一个表中可以有多个唯一约束
- 添加数据时唯一约束字段可以为空
检查约束
create table 表名 (字段名 字段类型 check (检查约束条件));alter table 表名 add constraint 检查约束名 check (检查约束条件);- 注意:mysql中检查约束不会进行报错
默认值约束
create table 表名 (字段名 字段类型 defalut 默认值);alter table 表名 modify 字段名 字段类型 defalut 默认值;alter table 表名 alter column 字段名 DROP DEFAULT
外键约束
create table 表名 (字段名 参照表名 参照表字段名 foreign key (字段名) references 参照表名(参照表字段名));alter table 表名 add constraint 外键名 foreign key 字段名 references 参照表名(参照表字段名);
索引
普通索引
create index 索引名 on 表名(字段名);alter table 表名 add index 索引名(字段名);drop index 索引名 on 表名;- 普通索引通常使用bTree
- 普通索引找到符合的选项后会继续向下找直到最后
唯一索引
create unique index 索引名 on 表名(字段名);alter table 表名 add unique 索引名 (字段名);- 唯一索引找到符合的值后就返回
主键索引
alter table 表名 add primary key (字段名);- 主键索引必须唯一,而且非空
- 添加主键索引其实就是添加主键约束
全文索引
create table 表名 (字段名 字段类型,..., fulltext (字段名, ...));
MySQL 权限与用户管理
delete from 数据库.表名 where host='允许访问的地址' and user='用户名'
限制账户资源
- max_questions:用户每小时允许执行的查询操作次数
- max_updates:用户每小时允许执行更新操作次数
- max_connections:用户每小时允许执行的连接操作次数
max_user_connections:用户允许同时建立的连接次数
grant select on 数据库名.表名 to '用户名'@'允许访问的地址' with max_questions_per_hour 3 max_user_connections 5;alter table '用户名'@'允许访问的地址' with max_queries_per_hour 50;create user '用户名'@'允许访问的地址' identified by '密码' with max_queries_per_hour 20
设置密码
set password for '用户名'@'允许访问的地址'=PASSWORD('新密码');grant usage on 数据库名.表名 to '用户名'@'允许访问的地址' identified by '新密码';
事务
事务必须同时满足 ACID 四个条件:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
- 原子性:事务中所有的操作,要么全部执行,要么全不执行,若中途发生异常,会回滚。
- 一致性:事务从开始到结束,数据库都具有完整性,这是对数据库层面和应用层面的双重保障。
- 隔离性:用来保证多个并发事务对数据进行操作,不会发生受到干扰。
- 持久性:用来保证事务提交后,对数据的修改具有永久性。
数据库并发问题主要有以下三类:
- 脏读:当前事务读到其他事务未提交的数据。
- 幻读:事务 1 按照某个条件多次查询数据库,但每次查询的结果行数不同。
- 不可重复读:事务 1 多次读取同一数据资源,与此同时事务 2 对该数据进行了多次修改,这导致事务 1 每次读取的数据显示结果不同。
MySQL事务的隔离级别分为以下四种:
- 读未提交(READ-UNCOMMITTED):可能发生脏读、可幻读和不可重复读。
- 读已提交(READ-COMMITTED):可能发生幻读、不可重复读,不可能发生脏读。
- 可重复读(REPEATABLE-READ):可能发生幻读,但不会发生脏读和不可重复读。
- 串行化(SERIALIZABLE):不可能发生幻读、脏读、可重复读。
从事务理论的角度来看,可以把事务分为以下几种:
- 扁平事务(Flat Transactions):所有操作处于同一层次,要么都执行,要么回滚。 带有保存点的扁平事务(Flat Transactions with Savepoints):保存点是用来通知系统应该记住事务当前的状态,以便在发生错误时,可以回滚到保存点的状态。
- 链事务(Chained Transactions):在提交一个事务时,释放不需要的数据对象,将必要的处理上下文隐式地传递给下一个开始事务,下一个事务会看到上一个事务的结果。
- 嵌套事务(Nested Transactions):是一个层次结构的框架,由一个顶层事务控制着各个层次的事务,顶层之下的事务称为子事务,子事务控制着每一个局面的变化。
- 分布式事务(Distributed Transactions):通常是一个在分布式环境下运行的扁平事务,因此需要根据数据所在的位置访问网络中的不同节点。
SELECT @@TX_ISOLATION; - 查看事务隔离级别
事务的控制语句
BEGIN或START TRANSACTION- 显式地开启一个事务COMMIT或COMMIT WORK- 提交事务,并使已对数据库进行的所有修改成为永久性的ROLLBACK或ROLLBACK WORK- 结束用户的事务,并撤销正在进行的所有未提交的修改SAVEPOINT <identifier>- 允许在事务中创建一个 SAVEPOINT,一个事务中也可以有多个 SAVEPOINTRELEASE SAVEPOINT <identifier>- 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常ROLLBACK TO <identifier>- 把事务回滚到标记点SET TRANSACTION- 用来设置事务的隔离级别SET AUTOCOMMIT = 0或SET AUTOCOMMIT = 1- 关闭/开启自动提交
存储引擎
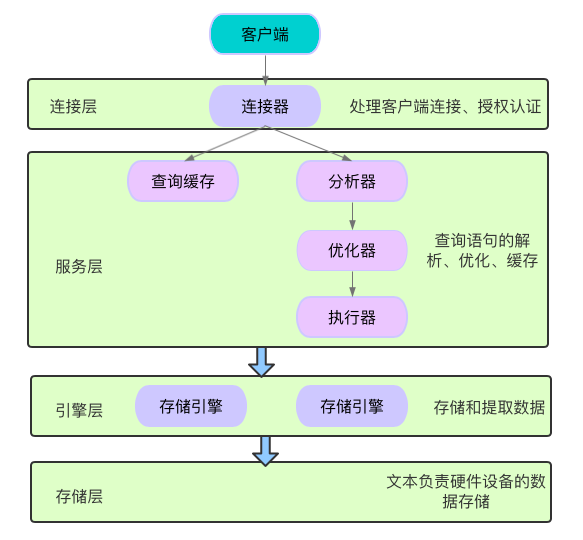
SHOW ENGINES\G; 或 SELECT * FROM INFORMATION_SCHEMA.ENGINES\G; - 查看存储引擎
MyISAM存储引擎
- .frm 文件存储表的定义数据
- .MYD(MYData) 存放表具体记录的数据
.MYI(MYIndex) 文件用来存储索引
数据文件和索引文件可以放置在不同的目录下,获得更快的速度。
- 当按排序顺序插入行时,比如,使用 AUTO_INCREMENT 列时,索引树将被拆分,以便高级节点仅包含一个键,这样可以提高索引树的空间利用率。
- AUTO_INCREMENT 支持每个表对一列数据的内部处理。MyISAM 自动更新此列的 INSERT 和 UPDATE 操作。这使得 AUTO_INCREMENT 列会更快。
- 当表损坏时,MyISAM 类型的表提供修复工具,可以使用 CHECK TABLE 来检查表的情况,并且可用 REPAIR TABLE 来修复。
MyISAM支持三种存储格式:
- 静态固定长度表:默认存储格式,存储速度快、易缓存、易修复,但是占空间。
- 动态可变长度表:由于记录不是固定长度,所以能够节省空间,但发生错误后,不易恢复。
- 压缩表:占用磁盘空间小,当数据文件发生错误时,可检查也可恢复。
create table 表名(字段名 字段类型,...) engine=MyISAM; - 创建MyISAM存储引擎的表
MEMORY存储引擎
- .frm 文件存储表和数据
- MEMORY 支持 HASH 和 BTREE 这两种索引的数据结构,默认的是 HASH 索引。
- 支持的数据类型有限制,例如,不支持 TEXT 和 BLOB 类型,VARCHAR 会被自动存储为 CHAR 类型。
- 数据存储在内存中,一旦服务器出现故障,数据都会丢失。
create table 表名(字段名 字段类型,...) engine=MyISAM; - 创建MEMORY存储引擎的表
ARCHIVE存储引擎
- ARCHIVE 存储引擎将产生大量未索引数据存储在一个小的专用表里。
- 创建 ARCHIVE 表时,服务器会在数据库目录中创建表格式文件。该文件以表名开头,并具有 .frm 扩展名。存储引擎创建其他文件,所有文件的名称均以表名开头。数据文件的扩展名为 .ARZ。在 .ARN 优化过程中,操作文件可能会出现。
- ARCHIVE 存储引擎支持 INSERT,REPLACE 和 SELECT 操作,但是不支持 DELETE 或者 UPDATE 操作。它支持 ORDER BY 操作,BLOB 列以及基本上所有的数据类型,包括空间数据类型。
- 压缩协议进行数据存储只允许自增 id 列建立索引。
- ARCHIVE 存储引擎主要会应用在日志系统或者设备数据中
create table 表名(字段名 字段类型,...) engine=ARCHIVE; - 创建ARCHIVE存储引擎的表
InnoDB存储引擎
- MySQL中只有InnoDB支持外键
- InnoDB 存储引擎支持事务,它的操作遵守 ACID 原则,并具有提交、回滚和恢复的功能去保护用户的数据。
- 具有行级锁,提高多用户并发性。
- InnoDB 表将数据存放在磁盘上,基于主键优化查询,每个 InnoDB 都有一个称为聚集索引的主键索引。
- InnoDB 存储引擎支持外键约束,能够维护数据的完整性,使用外键检查 INSERET,UPDATE 和 DELATE 操作,以确保它们不会导致不同表之间的不一致。
- 如果服务器因为软件或者硬件问题而崩溃,InnoDB 会自动恢复到崩溃之前已经提交的所有更改处,仅需重启并从上次中断的地方继续即可。
- InnoDB 存储引擎会维护它自己的缓冲池,在主内存缓存表和索引数据作为数据被访问,这个缓存适用于多种类型的信息并且加快处理速度。
- 如果将数据拆分到不同的表里,设置外键去增强完整性。更新或者删除数据,会自动更新或者删除其他表里的相关数据。
- 创建数据库并在每张表中设置合适的主键后,这些列操作会自动进行优化。
- 能够压缩表和关联索引。
- 能够创建和删除索引,对性能的影响很小。
- 能够通过查询 INFORMATION-SCHEMA 表来监控存储引擎的内部工作情况。
- 可以通过查询 Performance Schema 表去监控存储引擎的性能详细信息。
- 能够将 InnoDB 表和其他存储引擎表混合使用,例如,可以使用联接操作在单个查询中合并来自 InnoDB 和 MEMORY 表中的数据。
InnoDB的锁
MySQL中有三种锁:
- 表级锁:开销大,加锁快,不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度低。
- 行级锁:开销大,加锁慢,会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间,会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
- InnoDB支持行级锁和表级锁,默认采用行级锁
InnoDB中两种类型的行锁:
- 共享锁(S):允许一个事务读一行数据,阻止其他事务获得相同数据集的排他锁。
- 排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同的数据集的共享锁和排他写锁。
InnoDB中两种意向锁,均为表锁,是为了实现行锁和表锁共存,意向锁锁InnoDB自动添加的
- 意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁。
- 意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的 IX 锁。
SELECT * FROM <表名> WHERE <条件> LOCK IN SHARE MODE; - 给表添加共享锁
SELECT * FROM <表名> WHERE <条件> FOR UPDATE; - 给表添加排他锁
行锁的实现:通过对索引上对索引项添加锁来实现,如果没有索引,就给主键(或隐藏主键)索引记录加锁
- 记录锁 (Record Lock):锁定的是索引记录。
- 间隙锁(Gap Lock):对索引之间的间隙锁定,也能对第一个或最后一个索引记录之前的间隙锁定。
- 临键锁(Next-Key Lock):间隙锁和记录锁的一个组合,对记录和前面的间隙加锁,用来解决数据库的幻读问题。
行锁是通过索引上对索引项来实现的,只有通过索引条件来检索数据才使用行级锁,否则使用表级锁
SHOW FULL PROCESSLIST\G; - 查看当前线程处理情况,对处理突发事件非常有用
SHOW ENGINE INNODB STATUS\G; - 查询 InnoDB 当前锁请求的信息
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX\G; - 查看当前运行的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS\G; - 查看当前出现的锁
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS\G; - 查看锁等待的对应关系
MySQL优化
数据表优化
- 设计表尽量避免NULL出现,可以使用0来代替
- 尽量使用int而不是bigint
- 使用枚举或整数代替字符串类型
- 尽量用timestamp代替datetime
- 尽量不使用like语句,不要在列上进行运算
- 不要使用not in,可以用not exists代替
表中数据类型的优化
select * from 表名 procedure analyse()\G;- 查看表中是否有可以优化的列analyze table 表名;- 分析和存储表的关键字分布,这个分析结果可以让SQL生成正确的执行计划check table 表名;- 检查表是否有错误,只对MyISAM有效optimize table 表名;- 优化表,对MyISAM和InnoDB都有效
索引优化
- 尽量在where和order by命令涉及的列建索引
- 通过explain查看是否使用到了索引
- 避免在where中使用null判断,会放弃使用索引
- 值分布很少的字段不适合添加索引,字符字段只做前缀索引,字符字段不要做主键,尽量不用unique,由应用约束
查询的性能优化
show session status;- 当前连接的统计结果show global status;- 自数据库上次启动到现在到统计结果- Com-select: 执行 SELECT 操作的次数,查询一次计数会增加一次。
- Com-insert: 执行 INSERT 操作的次数,对于一次性插入多行数据,仅记为一次插入。
- Com-update: 执行 UPDATE 操作的次数。
- Com-delete: 执行 DELETE 操作的次数。
SHOW INDEX FROM <表名>;- 可以查看某表的索引情况- Non_unique 是索引是否有重复值,若无重复值则为 0,否则为 1。
- Key_name 是索引的名字。
- Seq_in_index 是索引中的列序号,从 1 开始。
- Collation 是列存储在索引中的方式,NULL 代表无分类,A 代表升序。
- Cardinality 是索引中唯一值的数目估计值。
- Sub_part 是前置索引,如果列只是部分被编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为 NULL。
- Packed 是说明关键字如何被压缩,若未被压缩,则为 NULL。
- Index_type 是索引类型。
- Comment 是在其列中没有描述的索引的信息。
- Index_comment 是为索引创建时提供了一个注释属性索引的任何评论。
EXPLAIN SELECT COUNT(*) FROM employee USE INDEX (idx_id_name)\G;- 建议查询器使用某个索引查询EXPLAIN SELECT COUNT(*) FROM employee IGNORE INDEX (idx_id_name)\G;- 忽略某个索引查询EXPLAIN SELECT * FROM employee FORCE INDEX(idx_salary) WHERE salary < 6000\G;- 强制使用某个索引查询
日志
错误日志(error log)
记录 MySQL 服务器在启动、停止和运行过程中发生任何严重警告和错误的信息
SHOW VARIABLES LIKE 'LOG_ERROR'; - 查看错误日志的存放位置
中继日志(relay log)
用于主从复制,临时存储从主库同步的二进制日志
SHOW VARIABLES LIKE '%RELAY%'; - 查看中继日志的具体信息
max_relay_log_size- 是中继日志允许的最大值,若该值为 0,则默认其最大值为 1 G。relay_log- 定义了中继日志的位置和名称,若值为空,则是在数据文件的默认位置。relay_log_basename- 也是定义了中继日志的位置和名称。relay_log_index- 定义了中继日志索引的位置和名称。relay_log_info_repository- 确定中继日志是放在 FILE 还是 TABLE 里。relay_log_purge- 是否自动清空中继日志,ON 为启动。relay_log_recovery- 当中继日志损坏,是否保存所有未执行的中继日志,OFF 为关闭。relay_log_space_limit- 设置中继日志最大限额。sync_relay_log- 是否把日志写入缓存。
慢查询日志(slow query log)
慢查询日志是用来记录所有执行时间超过 long_query_time 秒的所有查询,其 long_query_time 的默认值为 10 秒
SHOW VARIABLES LIKE '%QUERY%'- 查看慢查询配置long_query_time- 指定慢查询的时间阀值,默认为 10。slow_query_log- 是否开启慢日志,默认是关闭。slow_query_log_file- 是记录慢日志到文件中的路径
SET GLOBAL SLOW_QUERY_LOG=ON/OFF;- 开启/关闭慢查询日志SET GLOBAL LONG_QUERY_TIME=5;- 修改阈值
二进制日志(binary log)
二进制日志是记录了所有的数据库定义和操纵语句,当数据库内容变化时,会产生二进制文件,也被用来实现主从复制,主要有三种格式
- STATEMENT 是语句格式,通过 mysqlbinlog 工具可以清楚看到每条语句的文本。
- ROW 是将每一行变更记录到日志中。
- MIXED 是混合了 STATEMENT 和 ROW 这两种格式。
SHOW VARIABLES LIKE '%LOG_BIN%' - 查看二进制日志的相关信息
- log_bin:记录二进制日志是否开启。
- log_bin_trust_function_creators:是否允许用户创建和更改存储函数,默认是 OFF。
- log_bin_use_v1_row_events:二进制日志的版本信息,默认为 OFF。
- sql_log_bin:是否停止对二进制的写入。
SHOW BINARY LOGS; - 查看当前使用了哪些二进制文件
SHOW BINLOG EVENTS\G; - 查看日志中进行了哪些操作
SHOW MASTER STATUS\G; - 查看当前二进制的位置
SHOW MASTER LOGS; - 显示服务器所有二进制文件
SET sql_log_bin=0/1; - 禁用/启用当前会话二进制日志
SET GLOBAL BINLOG_FORMAT='<格式名>' - 修改二进制日志的格式,可选值为statement、row、mixed
PURGE MASTER LOGS TO ‘<文件名>’ - 清空该文件中的日志
reset master - 删除所有日志
普通查询日志(general query log)
普通查询日志是记录客户端连接数据库执行语句时所产生的日志。 普通查询日志默认是关闭的
SHOW VARIABLES LIKE '%GENERAL_LOG%';- 查看一下普通查询日志是否开启SET GLOBAL GENERAL_LOG=ON/OFF- 开启/关闭普通查询日志SHOW VARIABLES LIKE '%LOG_OUTPUT%';- 查看普通查询日志输出格式SET GLOBAL LOG_OUTPUT='TABLE';- 普通查询日志输出格式改为table
元数据日志(metadata log)
数据库备份和恢复
逻辑备份
将数据库中表的数据以文本文件形式备份,可以使用mysqldump来实现
mysqldump [主机号][端口][用户名][密码][数据库名][表1][表2] > [文件名].sql - 备份指定数据库的多个表
mysqldump [主机号][端口号][用户名][密码] --databases [数据库名1][数据库名2] > [文件名].sql - 备份指定数据库全部内容
mysqldump [主机号][端口号][用户名][密码] --all-databases > [文件名].sql - 备份所有数据库
还可以使用mydumper命令进行备份,mydumper支持多线程,速度更快,功能也更多
物理备份
表空间的迁移技术
在迁移过程中,表仅处于只读状态,需要将 innodb_file_per_table 设置为 ON
SHOW VARIABLES LIKE '%PER_TABLE%'- 查看参数值SET GLOBAL innodb_file_per_table=ON- 设置参数为ONFLUSH TABLES <表名> FOR EXPORT- 锁定表,锁定后表无法执行增删查改操作
使用热备份工具备份
可以使用Xtrabackup热备份工具进行备份。备份分为全量、增量、日志备份。
数据恢复
使用mysqldump备份的数据可以通过 mysql -u root 数据库名 < 恢复文件名 进行恢复
文本文件可能进行了更改二进制文件恢复需要使用mysqlbinlog
mysqlbinlog [二进制日志文件名]|mysql -u root [数据库名] - 恢复数据后重做日志
使用mydumper备份的数据可以通过myloader进行恢复