一.Linux指令(centos)

1. 日常操作
1.1 cd 切换工作目录
全称:change directory
cd 目录 - 进入指定目录(相对路径和绝对路径均可)
cd ..- 返回上层目录
cd ~- 回到根目录
cd /- 进入系统根目录
cd -- 进入上次的工作目录
1.2 ls 查看文件信息
全称:list
ls - 查看当前文件夹下的内容
-l- 显示文件的详细信息
-a- 显示所有文件(包括隐藏文件)
-R- 递归显示所有内容
-S/-t- 按大小/时间排序
-h- 以人性化的方式进行显示(文件大小带单位)
-all- 显示所有文件的详细信息,可以简写问ll
注意: 多个功能不冲突的参数可以同时使用,中间用空格隔开, 例如 ls -lh -S
1.3 pwd 显示当前路径
全称:print work directory
pwd - 打印当前路径
1.4 touch 创建文件
全称:touch
touch 文件名 - 新建文件
1.5 cat 查看文件内容
全称: catenate/concatenate
cat 文件名 - 查看文件内容
cat 文件1 文件2>文件3 - 将文件1和文件2的内容放在文件3中
1.6 tail 查看文件内容
tail -f 文件名 - 实时查看文件内容(可以实时看到改动)
tail -n 数字 - 查看最后几条数据
1.7 rm 删除文件
全称:remove
rm 文件名 - 删除文件(询问是否删除)
-i- 询问是否删除(默认)
-f- 强制删除文件(不询问)
-r- 递归删除(删除文件夹)
(注意:cp/mv/rm 后面可以跟: -i询问 -f强制 -n不覆盖)
1.8 cp 复制文件
全称:copy
cp 文件名1 文件名2 - 将文件1中的内容拷贝到文件2中
cp 文件 目录 - 将指定文件拷贝到指定目录中
-r 文件名/目录名 目录2 - 将文件/目录拷贝到目录2中
-f - 禁止交互式操作,不会给出提示
(注意:cp/mv/rm 后面可以跟: -i询问 -f强制 -n不覆盖)
1.9 mv 移动文件
全称:move
mv 文件名1 文件名2 - 将文件1中的内容移动到文件2中 ,并且删除文件1(文件重命名)
mv 文件1路径 文件2路径 - 将文件夹1移动到文件夹2
mv 文件名1 新文件名 - 给文件重命名
-f - 禁止交互式操作,不会给出提示
注意: mv指令不能加-r来操作目录
(注意:cp/mv/rm 后面可以跟: -i询问 -f强制 -n不覆盖)
1.10 mkdir 创建文件夹
全称:make directory
mkdir 目录名 - 新建目录
-p- 递归创建目录
-p a/{b,c}/{d,e,f}- 同一层级创建多个
1.11 rmdir 删除文件夹
全称:remove directory
rmdir 目录名 - 删除指定空目录
1.12 history 查看历史命令
history - 显示历史指令记录
!历史命令编号- 执行历史命令
-c- 清除历史命令
bashrc 配置显示时间:export HISTTIMEFORMAT="%y‐%m‐%d %H:%M:%S "
修改bashrc 后使其生效: source ~/.bashrc或 ..bashrc
1.13 ln 链接
全称:link
ln 源路径 目标路径 - 给源路径对应的文件在目标路径下创建一个硬链接(看成一个数据的多个引用)
-s - 给源路径对应的文件在目标路径下创建一个软链接(快捷方式)
注意: 源文件不存在的时候,软件无效,硬链接变成普通文件
1.14 常用快捷键
ctr + f - 前进一个字符
ctr + b - 后退一个字符
ctr + a - 回到行首
ctr + e - 回到行尾
ctr + w - 向左删除一个单词
ctr + u - 向左删除全部
ctr + k - 向右删除全部
ctr + y - 粘贴上次删除的内容
ctr + l - 清屏
1.15 服务管理
systemctl start mysqld :启动mysql进程
systemctl stop mysqld :结束mysql进程
systemctl restart mysqld : 重启mysql进程
systemctl status mysqld : 查看进程状态
systemctl enable mysqld :开机自启动进程
netstat -ntlp 端口名 :查端口
-n- 以数字显示
-t- tcp端口
-l- 显示监听端口
-p- 显示 PID 和进程名称
2. 进程相关指令
2.1 ps 查看进程
全称: Processes Status
ps - 进程状态
-a- 查看所有进程
-u- 显示进程的详细状态
-x- 显示没有控制终端的进程
-w- 显示加宽,以便显示更多的信息
-r- 只显示正在运行的进程
-e- 显示所有进程
-f- 全部列出
常用ps -aux或者ps ex查看进程
ps -aux|grep 进程名 - 查看指定进程
2.2 top 动态查看进程
top - 动态监控进程
-p PID1,PID2,…- 动态监控指定进程
M- 按照内存使用量排序
P- 按照CPU使用量来排序
2.3 free 查看内存
free -单位 - 以指定单位查看内存, 例如 free -m (以Mb为单位显示内存状况), -g, -k等!
2.4 kill 杀死进程
kill 进程号 - 杀死指定的进程
kill -1/-9/-15 进程号
-1- (HUP)不间断重启
-9- (KILL)强制杀死进程
-15- (TERM)正常终止进程
pkill 进程名 - 按名字处理进程
killall 进程名 - 处理名字匹配的进程
2.5 uptime 查看系统状态
uptime - 查看系统状态
2.6 jobs 查看后台运行
jobs - 查看后台运行程序
命令 & - 进程后台运行
fg %后台进程号 - 将后台进程放在前台运行
bg %后台暂停的进程号 - 将后台任务运行
ctrl z - 将程序暂停后放在后台
2.7 pgrep搜索进程
pgrep 进程名 - 搜索进程
2.8 nohup不接受中断进程
nohup redis-server --requirepass 1qaz2wsx - 表示终端结束后redis不会停止
3. 用户和权限管理
3.1 users 查看用户
users - 查看所有用户
3.2 groups 查看当前用户组
groups - 查看当前分组
3.3 groupadd 添加分组
groupadd 分组名 - 添加分组 (能在/etc/group文件中查看到新的分组, root才有的权限)
3.4 useradd 添加用户
useradd 用户名 - 创建新的用户(还是在home中自动创建这个用户对应的文件夹, root才有的权限)
-G- 指定组名
-d- 指定用户登录系统时的主目录,如果不使用该参数,系统自动在/home目录下建立与用户名同名目录为主目录
-m- 自动建立目录
3.5 usermod 修改分组
usermod -G 分组列表 用户名 - 修改分组(root才有的权限)
3.6 passwd 更改用户密码
passwd 用户名 - 修改密码(root才有权限)
passwd - 修改当前账号密码
3.7 su 切换用户
su 用户名 - 切换用户身份(root不需要密码,其他用户需要密码)
sudo - 以管理员执行其他程序
注意:
在ubuntu需要将用户添加到sudo分组中,才能使用sudo以管理员的身份执行程序
在centOS中需要先执行vi 指令进入/etc/sudoers文件中在指定的位置添加内容
\## Allow root to run any commands anywhere
root ALL=(ALL) ALL
xiaoming ALL=(ALL) ALL (自己添加的,xiaoming是用户名)
3.8 chmod 权限更改
chmod 权限值 文件 - 修改指定文件的权限
chmod [a,u,g,o][+,-][r,w,x] 文件 - 为指定文件,给所有用户添加或删除相应的权限
3.9 chown 更改文件所有者
chown 用户名 文件 - 改变文件所有者
4. 日志管理
4.1 cat查看文件内容
cat 文件 - 查看文件内容
cat /proc/version - 查看linux版本和发行版本
cat /proc/cpuinfo - 处理器信息
cat /proc/net/dev - 查看网卡信息
4.2 head/tail 查看部分内容
head –n N 文件 - 查看前N行内容
tail –n N 文件 - 查看后N行内容
4.3 less/more 分页查看
more [-N] 文件 - 和less差不多,这个是尽可能多,less是尽可能少的加载
按 j 向下
按 k 向上
按 f 向下翻屏
按 b 向上翻屏
按 g 到全文开头
按 G 到全文结尾
按 Q 退出
4.4 sotr/uniq/awk/sed结果处理
sort - 排序(cat 文件 |sort)
-n- 按照数值大小排序
-r- 以相反的顺序来排序
uniq - 去重 (cat 文件 |uniq) - 只会去重相邻的重复是数据,一般结合sort一起使用|sort|uniq
-c- 去重的时候统计每一行内容的重复出现的次数
awk '{print $N}' - 打印第N列的内容(netstat -natp|awk '{print $4}')
awk '{print $N1,$N2,$N3,…}' - 打印多列内容,用空格分开
history |awk '{print $4}' |sort |uniq ‐c | sort ‐rnk 1 | head ‐n 3 -获取历史指令中,使用最频繁的三个指令
sort –n - 数值大小从小到大排序
sort - 字符大小从小到大排序(默认)
sort –rn - 数值大小从大到小排序
sort –r - 字符大小从大到小排序(默认)
4.5 >和>> 重定向
执行获取数据的指令 > 文件 - (将执行指定的结果存储到文件中 - 覆盖原文件中内容)
执行获取数据的指令 >> 文件 - (将执行指定的结果存储到文件中 - 在原文件的最后追加)
4.6 wc 统计
全称: Word Count
wc 文件名
-l- 统计行数
-w- 统计字数,跳过空白符
-c- 统计字节数
-m- 统计字符数(不能和-c一起用)
4.7 grep 文本搜索
grep 查看对象 目录/文件 参数
参数:
-i- 忽略大小写:grep you bb.txt -i
-n- 显示行标号:grep you bb.txt -n/grep you bb.txt -i –n
-r- 递归查找目录:grep –r you ./(在当前文件夹下中所有文件中去找包行’you’的行)
-E- 通过正则表达式匹配:grep -E '正则表达式' 文件
-v- 显示不包含匹配项的所有行,相当于取反:grep you bb.txt -v
注意: Linux中,正则不支持: \d,\s,\w,\b,\D,\S,\W,\B
支持:., +, *, ?, {N,M}, [], ^, $, |, ()
对文件格式进行约束
—include=‘*.py’ 仅包含 py文件: grep -r you ./ --include=‘*.py'
—exclude=‘*.js’ 不包含 js 文件:grep -r you ./ --exclude='*.js'
4.8 find 文件查找
find 路径 -name ‘*.xxx’ - 找到目录下所有名字匹配的文件: find a1 -name '*.txt'(在文件夹a1中找所有txt文件)
find 路径 -size +/-文件大小 例如: find ./ +20k (在当前目录下找文件大小大于20k的文件)
例:find ./ -size +20k -size -100k -name '*.txt' (找当前目录下大于20k并且小于100k的所有txt文件)
4.9 which 查指令
which 指令 - 精确查找当前可执行的指令
whereis 指令 - 查找所有匹配的命令(包括安装位置)
man 指令 - 使用指令手册
5. 网络管理
scp 本地路径 username@ip:远程路径 - 将本地文件上传到远程主机
ifconfig - 查看网卡状态
netstat -natp - 查看网络连接状态
netstat -natp|grep 端口号 - 查看指定端口的网络连接状态
ping 地址
ping -i 时间 地址
ping -c 次数 地址
telnet ip地址 端口 - 查看远程主机网络连接状况(需要telnet环境)
dig 地址 - 查看DNS(看域名对应的IP地址) (需要环境支持)
wget 地址 - 下载
6. 使用包管理工具
1.包管理工具:yum
yum search:搜索软件包,例如yum search nginx。
yum list installed:列出已经安装的软件包
yum install 安装包名:安装软件包,例如yum install nginx。
-y 所有询问均选择yes
yum remove:删除软件包,例如yum remove nginx。
yum erase 包名:卸载软件包,例如yum erase -y mariadb
yum update:更新软件包,例如yum update可以更新所有软件包,而yum update tar只会更新tar。
yum check-update:检查有哪些可以更新的软件包。
yum info :显示软件包的相关信息,例如yum info nginx。
2.包管理工具:rpm
rpm -ivh 包名.rpm :安装软件包
rpm -e 包名 :移除软件包
rpm -qa :查询软件包
3.源代码构建安装
wget 安装包的路径 - 下载安装包
gunzip/tar 压缩包 - 解压、解归档
./configure --prefix /usr/local/ - 设置安装路径
cd 安装包目录 执行: make && make install - 编译安装包程序
给可执行文件添加软连接到usr/bin目录下 - 添加快捷方式
压缩/解压缩和归档/解归档 - gzip /gunzip / xz / tar
7. 其他命令
clock -w - 将日期时间保存到bios
df -h - 查看磁盘空间
server iptables stop/start - 关闭/打开防火墙
find . -name "*.py" |xargs cat|grep -v ^$|wc -l - linux统计代码行数
du -h 文件夹名 - 显示文件夹占用详情
diff 文件1 文件2 - 比较两个文件的不同
二.VIM
1. vim常用配置
编辑 vim /etc/vimrc 文件
"设置语法高亮
syntax on
"设置显示行号
set nu
"设置tab对应的空格数量
set tabstop=4
set ts=4
"设置tab自动变空格
set expandtab
"设置自动缩进
set autoindent
"不高亮选中单词
set nohls
"与当前设备共享粘贴板
set clipboard+=unnamed
"设置光标高亮,cul为当前行,cuc为当前列
set cul
set cuc
"vim映射快捷键:
"命令模式按冒号进入末行模式
imap <F4> if __name__ == '__main__':
"不递归调用映射
inoremap _main if __name__ == '__main__':
2.保存和退出
w - 只保存(类似快捷键ctr+s)
q - 退出(在编辑区的内容全部都保存的情况下才有效)
wq - 保存并退出
q! - 强制退出(不保存修改信息)
3.光标操作
^(shift+6) - 移动到行首
$(shift+4) - 移动到行尾
G(shift+g) - 移动到文件末尾
行号G - 移动到指定行,例如:30G, 让光标直接跳转到行号是30的那一行
gg - 移动到文件开头
4.文本操作
dd - 删除光标所在的行
数字dd - 从光标所在行开始往后面开始删,删除指定数量行内容
:%d - 删除所有
yy - 复制光标所在的行
数字yy - 从光标所在行开始复制指定行数的内容
p - 将复制的内容粘贴到光标所在的位置
u - 撤销
ctr+r - 反撤销
:%!sort - 对内容排序(将一行内容看成一个字符串,然后按字符串大小进行排序)
:/正则表达式 - 搜索匹配正则表达式的内容,按回车回到命令模式后按n往前查找,按N往后查找
注意: 正则表达式除了表示次数的符号前需要加\,别的和python是一样的.例如:
:/\d\{2}- 查找两个数字
:/a\+- 查找a出现一次或者多次
:1,$s/被替换对象/替换内容/参数 - 将正则表达式匹配到的内容替换成指定内容
注意: 参数可以没有
g - 全局匹配
i - 忽略大小写
c - 替换时需要提示
e - 忽略错误
5.高级技巧
vim -d a.txt b.txt - 比较多个文件
vim a.txt b.txt c.txt d.txt - 打开多个文件,可以使用sp(横向分屏)vs(纵向分屏)来进行拆分窗口,然后使用:b num来选择使用当前光标所在屏幕显示哪一个文档
多行注释:
ctrl+v- 进入可视化块模式上下移动光标选中需要注释的代码
I(大i) - 进入插入模式
输入注释符号
按ese键完成
多行取消注释:
ctrl+v - 进入可视化块模式
上下移动光标选中需要注释的代码
按小d即可取消注释
6.遇到的坑
当按了#号打开了高亮模式后 :nohlsearch退出高亮模式
7. 录制宏
命令模式按q
给宏取名字a
三.Shell编程
1.shell简介
要写一个shell文件要先创建一个shell文件,给shell文件添加执行权限,选择解释器执行
1.1 创建shell文件
原则上shell程序可以写在任何文件中,但一般会在shell文件后加后缀.sh表示当前文件是shell文件
1.2 添加执行权限
shell需要可执行权限,一般通过:chmod u+x shell文件名 来添加可执行权限
1.3 编译器选择
/bin/sh shell文件 - 通过bash去执行shell程序
./shell文件 - 通过默认解释器去执行shell程序
#!/bin/bash - 在文件内添加解释器路径
注意:sh是一个指向bash的软链接
1.4 Shell使用Linux命令
命令直接使用:
ls
ls -lh
获取返回值:
# 变量=$(指令)
# 变量=`指令`
re1=$(ls)
re2=`pwd`
1.5 Shell文件执行区别
./script.sh必须是可执行文件(文件需要有可执行权限),产生一个子进程来执行脚本sh script.sh或bash script.sh产生一个子进程来执行脚本source script.sh默认在当前进程执行脚本
1.6 执行shell的参数传递
脚本内获取参数的格式:$n n代表参数位置
其他命令:
$#传递到脚本的参数个数$*用一个字符串显示所有传递的参数$$脚本运行的当前进程ID号$?显示最后命令的退出状态,0表示没有错误$0执行的文件名
2.注释与变量
2.1 注释
单行注释:单行注释就是在一行文字前加#
多行注释:
:<<EOF
多行注释1
多行注释2
多行注释3
...
EOF
# EOF可以用其他任何符号代替
2.2 变量声明
变量名=值
注意:=两边不能有空格,变量名由数字字母和下划线组成,数字不能开头,不能是关键字,多个单词用下划线隔开
shell中所有变量的赋值都是字符串
2.3 变量使用
$变量名
${变量名} - 推荐使用
注意:变量不存在不会报错,会获得一个空值,变量重新赋值不加$,只有使用变量采用$
2.3 只读变量
readonly 变量名
2.4 删除变量
unset 变量名
3.数组和字符串
3.1 字符串
shell脚本中双引号,单引号和没有引号都表示字符串
只有双引号字符串中可以出现变量和转义字符
字符串:下标:长度 - 获取指定下标开始,指定个数字符,返回一个新的字符串
${#字符串} - 返回字符串的长度
字符串运算符见4.4
3.2 数组
3.2.1 数组定义
Bash Shell 只支持一维数组(不支持多维数组),元素用空格分割
数组名=(值1 值2 值3 值4 ...)
用小括号括起来,每个元素之间用一个空格隔开
3.2.2 获取数组元素
数组[下标] - 获取指定下标对应的元素
数组[@]/数组[*] - 获取数组中所有的元素
注意:${数组名}获取的是该数组的第一个元素
${#数组[@]} / ${#数组[*]} - 获取数组元素个数
${#数组[下标]} - 获取数组中指定下标的元素的长度
4.Shell运算符
4.1 算术运算符
原生bash不支持数学操作,需要计算数字,需要用expr awk来操作
expr仅支持整数运算:
+ ``
echo 10+20 #10+20
echo `expr 10 + 20` #30
echo `expr 10 \* 20` #200
# 用乘号的时候需要用转义符号
echo "scale=3; 1/13"|bc #.076
注意:结果是true或false的值只能用来做判断,不能保存
4.2 关系运算符
比较的是数字大小
-eq - 判断是否相等
-ne - 判断是否不等于
-gt - 大于
-lt - 小于
-ge - 大于等于
-le - 小于等于
使用语法:[ 值1 关系运算符 值2 ]
注意:中括号内两边都有括号
4.3 布尔运算符(逻辑)
! - 逻辑非运算
-o - 逻辑或运算
-a - 逻辑与运算
4.4 字符串运算符
[ 字符串1 = 字符串2 ] - 判断两个字符串是否相等(等号两边有空格)
[ 字符串1 != 字符串2 ] - 判断两个字符串是否不相等
[ -z 字符串 ] - 判断字符串长度是否为0
[ -n "字符串" ] - 判读字符串长度是否不为0
[ $ 字符串 ] - 判断字符串是否是空串
5. 循环判断
5.1 if
if 条件语句1
then
满足条件1执行的代码
elif 条件语句2
then
满足条件2执行的代码
elif 条件语句3
then
满足条件3执行的代码
else
所有条件都不满足的代码
fi
5.2 for循环
for 变量 in 序列
do
循环体
done
# 遍历多个值
for char in "hello" "world"
do
echo ${char}
done
# 遍历数组
array=(10 20 'abc')
for x in ${array[@]}
do
echo ${x}
done
5.3 while循环
while 条件语句
do
循环体
done
# 计算1+2+...100
sum=0
i=1
while [ ${i} -le 100 ]
do
sum=`expr ${sum} + ${i}`
i=`expr ${i} + 1`
done
echo ${sum}
5.4 死循环
死循环: while : /while true
while :
do
# read加-p表示后面可以输入提示内容
read -p "请输入一个数字:" name
done
6.函数
6.1 函数定义
[ function ] 函数名 ()
{
函数体
[return 返回值]
}
[]的内容可以省略,return只能返回数字,范围为0到255
6.2 函数的调用
调用函数: 函数名
有参数: 函数名 实参1 实参2 实参3...
6.3 函数的参数
声明的时候不需要形参,直接在函数体中通过${N}来获取第N个实参
func2(){
echo 函数2被调用
echo 第一个参数:${1}
echo 第二个参数:${2}
echo 第三个参数:${3}
}
func2 10 20 "abcc"
6.4 执行shell传参
在执行shell的时候可以传参,在程序中通过${N}来访问传递的参数
echo shell文件执行指令:${0} #/home/stolen/shell/shell文件.sh
echo 第一个shell参数:${1} #你好
echo 第二个shell参数:${2} #123
/bin/sh /home/stolen/shell/shell文件.sh 你好 123
7.定时设置
使用crontab -e进入定时设置
格式:
* * * * * 命令
前五个星号分别表示:分钟 小时 日 月 周
四. Git
1. 使用准备
1.1 公钥生成:免密登录
本地进入~/.ssh目录
使用命令ssh-keygen生成公钥和私钥
ssh-keygen -t rsa -C 邮箱 -f 文件名
-t指定密钥类型,默认是 rsa ,可以省略。
-C设置注释文字,比如邮箱。
-B密钥长度
-f指定密钥文件存储文件名。
.pub就是公钥
在Linux中的免密登录位置:~/.ssh/authorized_keys文件中
1.2 linux安装git
源代码构建安装:
yum -y install libcurl-devel安装依赖包wget下载源代码安装包
tar -zxvf解压安装包,并进入该文件夹./configure --prefix /usr/local/git设置安装路径make && make install编译安装ln -s /usr/local/git/bin/git /usr/local/bin/git
2.git学习(授课)
配置用户名:git config --global user.name "用户名"
配置邮箱:git config --global user.email "邮箱地址"
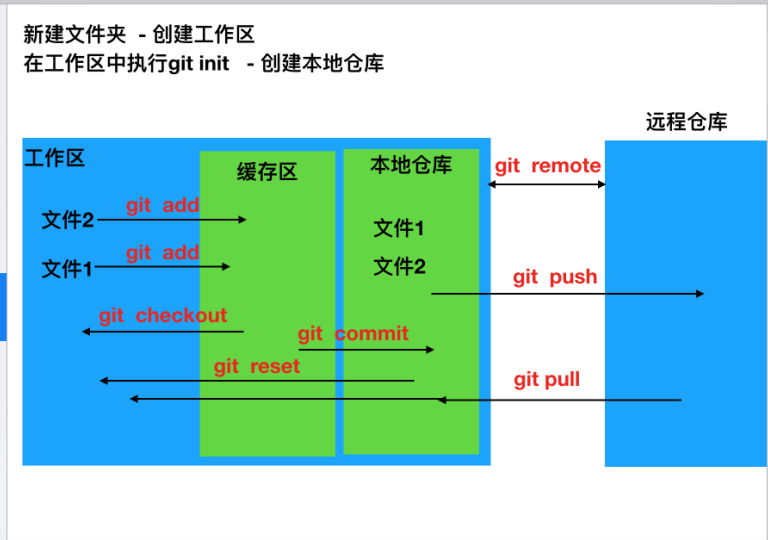
2.1 新建文件夹
创建工作区
2.2 本地仓库命令
git init - 创建本地仓库
git add 文件/文件夹 - 将文件添加到本地缓存区
git add -A - 将工作区所有文件添加到缓存区
git status - 查看文件状态
git commit -m 提示信息 - 将缓存区的文件添加到仓库
git log - 查看提交日志
git log --pretty=oneline - 查看提交日志(只包括版本号和备注)
git log --graph - 查看分支合并图
git reflog - 查看所有操作日志,包括已删除的版本
git reset --hard 版本号 - 回到指定的版本
git reset --hard HEAD^ - 回到上个版本
git reset --hard HEAD - 让仓库版本和工作区版本一致
git reset --hard HEAD~数字 - 向后回退多少个版本
git checkout 文件名 - 将缓冲区的文件还原到工作区
git rm --cached 文件名 - 将文件从暂存区删除
git stash - 将未做完的事情临时停下来压在栈中,不影响工作区.多次使用先进后出
pop - 继续未做完的事情.将其从栈中区出来
list - 查看栈中所有的事情.
2.3 远程仓库命令
git remote add origin 地址 - 将本地仓库和远程仓库进行关联(远程仓库必须为空)
git push -u origin master - 将本地仓库提交到远程仓库(第一次提交需要用-u),提交到master可以直接用git push,-u的全称为--set-upstream
git pull = git fetch + git merge
git remote -v - 查看当前仓库绑定的远端仓库
git push -u --force origin master - 强行推送代码到远端(远端就会被清空放当前的仓库)
git push - 直接将本地仓库的内容提交到远程仓库的当前的分支
--delete 分支名 - 删除远端分支
--tags - 将标签推送到服务器
如果文件内容发送冲突(CONFLICT)时,需要git pull先拉下来,然后和别人商量如何解决再提交
git pull - 将远程的仓库更新到本地仓库后,在将本地仓库更新到工作区
git clone - 将远程仓库克隆到本地,并且自动将本地仓库与远程仓库进行了关联(不用git remote)
--depth=1 - 只克隆最新版本
2.4 分支命令
git branch - 查看分支
-a - 查看所有分支
git branch 分支名 基于的分支名 - 创建分支
-d - 删除分支
-D - 强制删除分支
git checkout 分支名 基于的分支名 - 切换分支
-b - 创建并切换分支
git switch 分支名 基于的分支名 - 切换分支
-c - 创建并切换分支
git merge 分支名 - 当前分支去合并其他分支(只会将对方更改添加到自己的分支上)
--no-ff - 不使用快速合并(no fast forward),保存历史版本
git rebase 分支名 - 变基操作合并代码,先将开发线变为master线上的几个记录,然后合并.一定会保留历史记录
[develo]>>>git rebase master
[develo]>>>git switch master
[master]>>>git merge dev
git diff 分支1 分支2 - 查看两个分支的差异
2.5 标签
git tag 标签名 - 创建标签
git tag - 查看所有标签
git tag 标签名 commitID - 给指定commit id打标签
git tag -a 标签名 -m '标签信息' - 指定标签信息
git checkout 标签名 - 切换到指定标签
git show 标签名 - 查看说明文字
git tag -d 标签名 - 删除标签
git push origin 标签名 - 推送标签到远端
git push origin --tags - 一次性推送所有标签到远端
git push origin :refs/tags/标签名 - 将本地已经删除的标签推送到远端,删除远端标签
2.6 扩展
git add . - 将所有改动添加到缓存区
git rebase 分支名 - 将其他分支的改动合并到当前分支
git remote add origin http://....
(此处报错remote origin exist时,使用:git remote rm origin)
git flow - 使用git-flow流程化开发程序
五. Nginx服务框架
1. 安装与移除
yum -y install nginx 安装
安装完成后:
yum info nginx 查看nginx详情
nginx -v 查看nginx版本
yum -y remove nginx 移除
2. 启动nginx服务
systemctl start nginx 启动nginx服务
systemctl restart nginx 重启nginx服务
systemctl stop nginx 停止nginx服务
nginx -s stop 停止nginx服务
云服务器遇到端口报错解决办法:
打开80端口:
在网页控制台找到服务器网络和安全组中的安全组配置
在添加安全组规则中添加80端口就可以了
3. 配置nginx
配置文件目录:/etc/nginx/nginx.conf
在文件中的的location /{}的大括号中进行配置
#配置共享目录
root /home/stolen
location / {
autoindex on;
}
# 自定义服务器页面
location / {
# 设置网页目录地址
root /home/nginxHTML;
# 设置主页html文件名
index index.html index.htm;
}
4. uwsgi部署django项目
5. guncorn部署flask项目
六. MySQL
0. 数据库基础知识
0.1 数据库三范式
- 数据原子性,即数据不可再分(两行表示同一个人的数据)
- 数据的唯一性,保证有主键存在
- 数据的冗余性,(有一个学院表,学生信息中就不用写学院信息,只需要写学院编号即可)
0.2 数据库完整性:
- 实体完整性:每条记录都是唯一的,主键/唯一约束
- 参照完整性:外键
- 域完整性:数据库中的数据都是有效数据,数据类型/类型长度/非空约束/默认值约束/检查约束
0.3 数据库一致性:事务
1. 基本命令
- 启动服务
windows:net start 服务名称 (管理员身份运行)
linux:sudo systemctl start mysqld / sudo service mysql start
示例:net start mysql57 / service mysql start
- 停止服务
windows:net stop 服务名称 (管理员身份运行)
linux:systemctl stop mysqld / sudo service mysql stop
示例:net stop mysql57 / sudo service mysql stop
- 连接数据
格式:mysql -h ip地址 -u 用户名 -p
示例:mysql -u root -p
说明:连接本机-h参数可省略
- 退出登录
quit或exit
- 查看版本
select version()
- 查看帮助方式
格式:? 需要帮助的命令
示例:? data types;
2. 数据库操作(DDL)
2.1 创建数据库
格式:create database 数据库名 charset=utf8;
示例:create database stolen charset=utf8;
2.2 删除数据库
格式:drop database 数据库名;
示例:
drop database stolen;drop database if exists stolen
2.3 切换数据库
格式:use 数据库名;
示例:use stolen;
2.4 查看当前选择的数据库
select database();
2.5 查看所有数据库
show databases;
3. 表操作(DDL)
3.1 查看当前数据库中的所有表
show tables;
3.2 创建表
格式:create table 表名(列及类型);
auto_increment- 表明自增长primary key- 主键not null- 表示不为空default- 设置默认值unique- 值唯一primary key (sid, cid)- 设置联合主键unique(sid, cid)- 添加联合唯一约束
示例:create table student(id int auto_increment primary key, name varchar(20) not null, age int not null, gender bit default 1, address varchar(20), isDelete bit default 0);
3.3 删除表
格式:drop table 表名;
示例:drop table student;
drop table if exists student;
3.4 清空表中的数据
格式:truncate table 表名
示例:truncate table stolen
说明:此方法会彻底删除表,完全没有机会恢复
3.5 查看表结构
格式:desc 表名; / describe 表名;
示例:desc student;
3.6 查看建表语句
格式:show create table 表名;
示例:show create table student;
3.7 重命名表名
格式:rename table 原表名 to 新表名;
示例:rename table car to newCar;
3.8 修改表
格式:alter table 表名 add|change|modify|drop 列名 类型;
示例:alter table newCar add isDelete bit default 0;
alter table tb_student change column straddr foo varchar(100);
说明:change一定需要在column后面加一个旧的列名和新的列名,即使不修改列名都要有两个列名。
3.9 修改表(添加约束)
格式:alter table 表名 add constraint 索引名 约束 (字段名);
示例:alter table tb_student add constraint pk_stu_id primary key (stuid)
3.10 修改表(删除约束)
格式:alter table 表名 drop index 约束索引;
示例:alter table tb_student drop index pk_stu_id
3.11 view视图
创建:create view view_name as select...
更新:create or replace view view_name as select...
删除:drop view view_name
4. 数据操作(DML)
4.1 增加
- 全列插入
格式:insert into 表名 values(……)
说明:主键列事自动增长,但是再全列插入时需要占位,通常使用0,插入成功后以实际数据为准
示例:insert into student values(0,'tom',19,1,'北京',0);
- 缺省插入
格式:insert into 表名(列1,列2,……) values(值1,值2,……);
示例:insert into student(name,age,address) values('lilei',19,'上海');
- 同时插入多条数据
格式:insert into 表名 values(……),(……),……;
示例:insert into student values(0,'hanmeimei',18,0,'北京',0),(0,'poi',22,1,'海南',0),(0,'wenwen',20,1,'石家庄',0);
4.2 删除
格式:delete from 表名 where 条件;
示例:delete from student where id=4;
注意:没有条件是全部删除,慎用
4.3 修改
格式:update 表名 set 列1=值1,列2=值2,…… where 条件;
示例:update student set age=16 where id=7;
注意:没有条件是全部列都修改,慎用
4.4 查询
4.4.1 基本语法
格式:select * from 表名;
说明:
- from关键字后面是表名,表示数据来源于这张表
- select后面写表格中的列名,如果是
*表示在结果集中显示表中的所有列 - 在select后面的列名部分,可以使用as为列起别名,这个别名显示在结果集中
- 如果要查询多个列,之间使用逗号分隔
示例:
select * from student;select name,age from sutdent;
4.4.2 消除重复行
在select后面列前面加distinct可以消除重复的行
示例:
select gender from student;select distinct gender from student;
4.4.3 条件查询
- 语法
select * from 表名 where 条件;
比较运算符
等于:
=- 大于:
> - 小于:
< - 大于等于:
>= - 小于等于:
<= - 不等于:
!=或<>
示例:select * from student where id>8;
逻辑运算符
and- 并且or- 或者not- 非
需求:查询id值大于7的女同学
示例:select * from student where id>7 and gender=0;
- 模糊查询
like
%- 表示多个任意字符_- 表示一个任意字符[charlist]- 字符列中的任何单一字符[^charlist]或者[!charlist]- 不在字符列中的任何单一字符
示例:
select * from student where name like '习%';select * from student where name like '习_';范围查询
in- 表示在一个非连续的范围内between……and……- 表示在一个连续的范围内
示例:
select * from student where id in(8,10,12);select * from student where id between 6 and 8;空判断
注意:null与''是不同的
- 判断空:
is null - 判断非空:
is not null
示例:
select * from student where address is null;select * from student where address is not null;优先级
小括号,not, 比较运算符,逻辑运算符
and比or优先级高,如果同时出现并希望先选or,需要结合()来使用。
- 做判断显示
需求:查询性别,如果为0则显示女,如果为1则显示男
示例:
select stuname as 姓名, case stusex when 1 then '男' else '女' end as 性别 from tb_student;select stuname as 姓名, if(stusex, '男', '女') as 性别 from tb_student;
4.4.4 聚合
为了快速得到统计数据,提供了五个聚合函数
count(*)- 表示计算总行数,括号中可以写*和列名max(列)- 表示求此列的最大值min(列)- 表示求此列的最小值sum(列)- 表示求此列的和avg(列)- 表示此列的平均值
需求:查询学生的总数
示例:
select count(*) from student;select max(id) from student where gender=0;select min(id) from student where gender=0;select sum(age) from student where gender=0;select avg(age) from student;
4.4.5 分组
- 按照字段分组,表示此字段相同的数据会被放到一个集合中。
- 分组后,只能查询出相同的数据列,对于有差异的数据列无法显示再结果集中
- 可以对分组后的数据进行统计,做聚合运算
语法:
select 列1,列2,聚合…… from 表名 group by 列1,列2,列3……;select 列1,列2,聚合…… from 表名 group by 列1,列2,列3……having 列1,……聚合……
需求:查询男生女生总数
示例:
select name, gender,count(*) from student group by gender,age;select gender,count(*) from student group by gender having gender=0;
where与having的区别:
- where是对from后面指定的数据进行筛选,属于对原始数据进行筛选
- having是对group by的结果进行筛选
4.4.6 排序
语法:select * from 表名 order by 列1 asc|desc, 列2 asc|desc;
说明:
- 将数据按照列1进行排序,如果某些列1的值相同,则按照列2进行排序
- 默认按照从小到大的顺序排序
- asc升序
- desc降序
示例:
select * from student where isDelete=0 order by age desc;select * from student where isDelete=0 order by age desc,score asc;
4.4.7 分页
语法:
select * from 表名 limit start,count;select * from 表名 limit count offset start;
示例:
select * from student limit 0,3;select * from student limit 3,3;select * from student where gender=0 limit 0,3;
4.4.8 内连接
语法:
select 列1, 列2, 列3 from 表1 [表1别名], 表2 [表2别名], 表3 [表3别名] where 条件1, 条件2, 条件3;select 列1, 列2, 列3 from 表1 [表1别名] inner join 表2 [表2别名] inner join 表3 [表3别名] on 条件1, 条件2, 条件3
说明:使用inner join后连接条件需要用on,不使用inner join后连接条件使用where
4.4.9 外连接
左外连接语法:select 列1, 列2, 列3 from 表1 [表1别名] left outer join 表2 [表2别名] on 条件1, 条件2, 条件3
右外连接语法:select 列1, 列2, 列3 from 表1 [表1别名] right outer join 表2 [表2别名] on 条件1, 条件2, 条件3
说明:mysql不支持全外连接,其他数据库在不适用outer join时可以使用条件1(+)=条件2表示右外连接,条件1=条件2(+)表示左外连接,条件1(+)=条件2(+)表示全外连接,
4.4.10 交叉查询
select * from 表1名, 表2名;select * from 表1名 cross join 表2名;
4.4.11 union
UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
UNION ALL 命令和 UNION 命令几乎是等效的,不过 UNION ALL 命令会列出所有的值。
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2
4.5 关联
建表时添加外键语句:
create table class(id int auto_increment primary key, name varchar(20) not null,stuNum int not null);create table students(id int auto_increment primary key,name varchar(20) not null,gender bit default 1,classid int not null, foreign key(classid) references class(id));create table students(id int auto_increment primary key ,name varchar(20) not null,gender bit default 1,classid int not null foreign key(classid) references class(id) );
建表完成后添加外键:
alter table students add constraint 外键索引 foreign key (classid) references class (id)
说明:外键索引为自己命名,后面可以通过外键索引删除外键
关联查询:
select students.name as name,class.name as class from class inner join students on class.id=students.classid;
select students.name,class.name from class left join students on class.id=students.classid;
select students.name,class.name from class right join students on class.id=students.classid;
分类:
- 表A inner join 表B:
表A与表B匹配的行会出现在结果集当中
- 表A left join 表B:
表A与表B匹配的行会出现在结果集当中,外加表A中独有的数据,未对应的数据用null填充
- 表A right join 表B:
表A与表B匹配的行会出现在结果集当中,外加表B中独有的数据,未对应的数据用null填充
4.6 函数
字符串函数
| 函数 | 描述 | 实例 |
|---|---|---|
| ascii(s) | 返回字符串 s 第一个字符的 ASCII 码。 | select ascii('hello'); -- 104 |
| char_length(s) | 返回字符串 s 的长度 | select char_length('stolenzc'); -- 8 |
| character_lenght(s) | 功能同char_length(s) | select character_length("stolenzc"); -- 8 |
| concat(s1,s2...) | 连接多个字符串为一个字符串 | select concat('a','b','c'); -- abc |
| concat_ws(x,s1,s2...) | 用x字符拼接多个字符串 | select concat_ws('+','a','b','c'); -- a+b+c |
| field(s,s1,s2...) | 返回字符串 s 在字符串列表(s1,s2...)中第一次出现的位置 | select field('b','a','b','c'); --2 |
| find_in_set(s1,s2) | 功能同field(),s2是列表格式字符串 | select find_in_set("b", "a,b,c"); --2 |
| format(x,n) | 格式化数字x, 保留n位小数,最后一位四舍五入。 | select format(1234.1254, 2); -- 1,234.13 |
| insert(s1,x,len,s2) | 字符串 s2 替换 s1 的 x 位置开始长度为 len 的字符串 | select insert('abcde',3,2,'kkk'); -- abkke |
| locate(s1,s) | 从字符串 s 中获取 s1 的开始位置 | select locate('cd','abcdcd'); -- 3 |
| position(s1 in s) | 从字符串 s 中获取 s1 的开始位置 | select position('b' in 'abc') -- 2 |
| lcase(s) | 将字符串转换为小写 | select lcase('ABCd'); -- abcd |
| lower(s) | 将字符串转换为小写 | select lower('ABCd'); -- abcd |
| ucase(s) | 将字符串转换为大写 | select ucase("abcD"); -- ABCD |
| upper(s) | 将字符串转换为大写 | select upper("abcD"); -- ABCD |
| left(s,n) | 返回字符串 s 的前 n 个字符 | select left('abcd',2); -- ab |
| right(s,n) | 返回字符串 s 的后 n 个字符 | select right('abcd',2) -- cd |
| lpad(s1,len,s2) | 在字符串 s1 的开始处填充字符串 s2,使长度达到 len | select lpad('abc',5,'xx'); -- xxabc |
| rpad(s1,len,s2) | 在字符串 s1 的结尾处填充字符串 s2,使长度达到 len | select rpad('abc',5,'xx'); -- abcxx |
| ltrim(s) | 去掉字符串 s 开始处的空格 | select ltrim(" abc"); -- abc |
| rtrim(s) | 去掉字符串 s 结尾处的空格 | select rtrim("abc ") ; -- abc |
| trim(s) | 去掉字符串 s 开始和结尾处的空格 | select trim(' abcd ') -- abcd |
| mid(s,n,len) | 从 s 的 n 位置截取长度为 len 的子串 | select mid("abcd", 2, 2); -- bc |
| repeat(s,n) | 将字符串 s 重复 n 次 | select repeat('abc',3); -- abcabcabc |
| replace(s,s1,s2) | 将字符串 s2 替代字符串 s 中的字符串 s1 | select replace('abc','a','x') --xbc |
| reverse(s) | 将字符串 s 的顺序反转 | select reverse('abc') -- cba |
| space(n) | 返回 n 个空格 | select space(10); -- 输出10个空格 |
| strcmp(s1,s2) | 比较 s1 和 s2,相等返回 0 ,s1 大 返回 1,s2 大 返回 -1 | select strcmp("abc", "abd"); -- -1 |
| substr(s,start,len) | 从字符串 s 的 start 位置截取长度为 len 的子字符串 | select substr("RUNOOB", 2, 3); -- UNO |
| substring() | 参数功能同substr | select substring("RUNOOB", 2, 3); -- UNO |
| substring_index(s,d,n) | 返回从字符串 s 的第 n 个出现的分隔符 d 之前的子串 | select substring_index('a*b*c','*',2); -- a*b |
| substring_index(s,d,n) | n 是负数,返回第(n 的绝对值(从右边数))个分割符右边的字符串 | select substring_index('a*b*c*d*e','*',-3); -- c*d*e |
Mysql中Date函数
| 函数 | 描述 | 实例 |
|---|---|---|
| now() | 返回当前的日期和时间 | select now(); |
| curdate() | 返回当前的日期 | select curdate(); |
| curtime() | 返回当前的时间 | select curtime(); |
| date(date) | 提取日期或日期/时间表达式的日期部分 | select date(created_time) from user; |
| date_format(date,format) | 格式化输出日期 | select date_format(created_time, '%Y-%m-%d') from user; |
ifnull(data, result) - mysql中使用ifnull函数,如果data字段为null,则返回result的内容
4.7 变量
局部变量:
只能用在begin/end语句块中,比如存储过程中的begin/end语句块。其作用域仅限于该语句块。
声明:declare age int default 0;
赋值:set age=18;
select StuAge into age from demo.student where StuNo='A001';
用户变量:
mysql中用户变量不用提前申明,在用的时候直接用“@变量名”使用就可以了,其作用域为当前连接。
声明:set @age=19
set @age:=20
select @age:=22
会话变量:
mysql会话变量,服务器为每个连接的客户端维护一系列会话变量。其作用域仅限于当前连接,即每个连接中的会话变量是独立的。
-- 显示所有的会话变量
show session variables;
-- 设置会话变量的值的三种方式
set session auto_increment_increment=1;
set @@session.auto_increment_increment=2;
set auto_increment_increment=3; -- 当省略session关键字时,默认缺省为session,即设置会话变量的值
-- 查询会话变量的值的三种方式
select @@auto_increment_increment;
select @@session.auto_increment_increment;
show session variables like '%auto_increment_increment%'; -- session关键字可省略
-- 关键字session也可用关键字local替代
set @@local.auto_increment_increment=1;
select @@local.auto_increment_increment;
全局变量:
全局变量影响服务器整体操作,当服务启动时,它将所有全局变量初始化为默认值。要想更改全局变量,必须具有super权限。其作用域为server的整个生命周期。
-- 显示所有的全局变量
show global variables;
-- 设置全局变量的值的两种方式
set global sql_warnings=ON; -- global不能省略
set @@global.sql_warnings=OFF;
-- 查询全局变量的值的两种方式
select @@global.sql_warnings;
show global variables like '%sql_warnings%';
4.8 补充知识
查询中,别名的as全称为alias,as是可以省略的
在判断1显示男,0显示女中,case语法是数据库通用语法,if语法是mysql独有的方法
floor 意为地板,表示向下取整,ceil意为天花板,表示向上取整
round为四舍五入函数
datediff为计算日期差,可以用来计算生日
查询函数帮助使用? functions
concat为字符串连接函数
在数据库通用语言中,不等号用<>表示,!=为mysql中独有
连接查询时,不写条件就会产生卡迪尔积
连接查询如果使用临时表,必须取别名
/*查询的终极格式:
select ...
from ...
where ...
group by ...
having ...
order by ...
limit ...offset ...
*/
5. 权限用户操作DCL
5.1 创建远程连接的用户:
格式:create user '用户名'@'地址' identified by '密码'
说明:地址为能访问的IP地址,%表示所有用户,localhost表示本机;密码为该用户登录数据库的密码
示例:create user 'root'@'%' identified by '123456';
5.2 给用户授予指定的权限:
格式:grant 权限说明 on 数据库名.数据表名 to '用户名'@'地址' 该用户是否能操作权限;
说明:
- 权限说明:all privileges表示添加所有权限,其他具体的权限参照 https://dev.mysql.com/doc/refman/5.7/en/privileges-provided.html ;
*表示通配,*.*表示所有数据库的所有表;%表示所有地址- with grant option表示该用户能够管理其他用户的权限
示例:grant all privileges on *.* to 'root'@'%' with grant option;
5.3 移除用户的权限
格式:revoke 权限类型 on 数据库.对象 from 用户名
示例:revoke all privileges on school.* from 'stolen';
5.4 查看用户的权限
格式:
show grants for '用户名';select * from mysql.user where user='用户名'\G;
示例:
show grants for 'root';select * from mysql.user where user='root'\G;
5.5 刷新权限
格式:flush privileges;
5.6 修改用户名
格式:rename user '旧用户名'@'旧地址' to '新用户名'@'新地址';
5.7 删除用户
格式:drop user '用户名'@'允许访问的地址';
6. 数据库导入导出
导出:mysqldump -u 用户名 -p -d --add-drop-table 数据库名 表名 > 导出文件名;
说明:-d表示只导出结构,不导出数据;--add-drop-table每句前面添加drop table;如果不写表名,表示导出整个数据库。
注意:命令在系统命令行执行,不是在mysql中执行
导入:source 文件路径;
说明:在mysql的命令行下执行
加载:load data infile '加载数据文件路径' into table 表名;
7. 其他语法
格式:set global sql_safe_updates=off
说明:将数据库的安全更新模式关闭(celery保存数据库迁移表失败解决办法)
格式:ALTER TABLE user AUTO_INCREMENT = 5;
说明:设置自增字段的起始值
格式:explain 查询语句
说明:查看sql语句执行计划
格式:set foreign_key_checks=0;
说明:当表格有外键关联时,无法使用truncate截断表,可以使用关闭外键检查进行截断表
格式:select @@tx_isolation;
说明:查看事务隔离级别,
事务隔离会出现的问题:
第一类丢失更新:事务A撤销时,把事务B提交是数据覆盖了
第二类丢失更新:事务A提交时,把事务B提交的数据覆盖了
脏读:事务A修改的数据未提交被事务B读走了。
不可重复读:事务A中读取一次数据后,事务B修改了数据,事务A第二次读取数据为修改后的值
幻读:事务A执行一个查询后,事务B插入数据,事务A返回查询结果中包含了B插入的数据
事务隔离级别:
none - 未设置,会出现所有的问题
read uncommitted - 读未提交,可以避免第一类更新
read committed - 读提交,可以避免第一类更新,脏读
repeatable read - 可重复读,存在幻读问题
serializable - 所有问题都不会出现,性能最差
格式:set session transaction isolation level read committed
说明:设置事务隔离级别,
格式:update usercourses set exam_progress=floor(rand()*10);
说明:向数据库中插入随机数,rand()表示0到1之间到随机数,floor表示向下取整,向上取整用ceiling
8. 重要说明
sql语言对大小写不敏感
数据库常用的数据类型:
int/integer(-128到127)
float(size,d)/double(size,d) - 这儿的size和d的值都有约束效果
decimal(m,d) m表示最大长度,不包括小数点,d表示小数位数
char(size)-定长字符
varchar(size)-不定长字符串,size决定的是最大长度
text: 不限长度(最大是255个字符)
bit: 只有0和1两个值
date/datetime/time: 值可以是时间函数的结果,也可以时间字符串;计算或者是比较的时候内部是按时间处理的
值的问题: sql中是数字对应的值直接写,字符串需要使用引号引起来,bit类型的值只有0或者1, 时间可以用内容是满足时间格式字符串也可以是通过时间函数获取的值
-- 时间函数: now() - 当前时间包括日期 date(now()) - 当前日期 year(now()) - 当前年 month(now()) - 当前月 ....
左连接:左边表的数据全部显示出来,右边没有匹配的记录用空来代替
右连接:右边表的数据全部显示出来,左边没有匹配的记录用空来代替
内连接:两张表都有的数据才显示出来。
外连接/全连接:两张表的内容全部显示出来,没有匹配的数据用空来代替
9. SQL安全
sql注入攻击:
# 某网站的用户验证语句
strSQL = "SELECT * FROM users WHERE (name = '" + userName + "') and (pw = '"+ passWord +"');"
# 用户输入:
userName = "1' OR '1'='1";
passWord = "1' OR '1'='1";
# 以上代买会变成
strSQL = "SELECT * FROM users WHERE (name = '1' OR '1'='1') and (pw = '1' OR '1'='1');"
# 实际执行为
strSQL = "SELECT * FROM users;"
# 即实现无账号登录
解决办法:不使用字符串拼接,验证用户登录
七. mongoDB
1. 操作mongodb数据库
1.1 创建数据库
语法:use 数据库名
说明:如果数据库不存在,则创建数据库,否则切换到指定的数据库
注意:如果刚刚创建的数据库不在列表内,如果要显示它,我们需要向刚刚创建的数据库中插入的一些数据(db.student.insert({name:'tom',age:18,gender:1,address:'北京',isDelete:0}))
1.2 删除数据库
前提:使用当前数据库(use 数据库名)
db.dropDatabase()
1.3 查看所有数据库
show dbs
1.4 查看当前正在使用的数据库
a、db
b、db.getName()
1.5 断开连接
exit
1.6 查看命令api
help
2. 集合操作
2.1 查看当前数据库下有哪些集合
show collections
2.2 创建集合
a、
语法:db.createCollection('集合名')
示例:db.createCollection('class')
b、
语法:db.集合名.insert(文档)
示例:db.student.insert({name:'tom',age:18,gender:1,address:'北京',isDelete:0})
区别:两者的区别在于前者创建的是一个空的集合,后者创建一个空的集合并添加一个文档
2.3 删除当前数据库中的集合
语法:db.集合名.drop()
示例:db.class.drop()
3. 文档操作
3.1 插入文档
a、使用insert方法插入文档
语法:db.集合名.insert(文档)
插入一个:db.student.insert({name:'lilei',age:19,gender:1,address:'北京',isDelete:0})
语法:db.集合名.insert([文档1,文档2,……])
插入多个:db.student.insert([{name:'hanmeimei',age:19,gender:0,address:'北京',isDelete:0},{name:'韩梅梅',age:20,gender=0,address:'北京',isDelete:0}])
b、使用save方法插入文档
语法:db.集合名.save(文档)
说明:如果不指定_id字段,save()方法类似于insert()方法,如果指定_id字段,则会更新_id字段的数据
示例1:db.student.save({name:'pol',age:22,gender:1,address:'石家庄',isDelete:0})
示例2:db.student.save({_id:ObjectId("5d05c234ea833bab0c862e2b")},age=20)
3.2 文档更新
a、update()方法用于更新已存在的文档
语法:
db.集合名.update(
<query>,
<update>,
{
upset:<boolean>
multi:<boolean>
writeConcern:<document>
}
)
参数说明:
query:update的查询条件,类似于sql里update语句内where后面的语句
update:update的对象和一些更新的操作符($set,$inc)等,$set直接更新,$inc在原有基础上累加后更新
upset:可选,如果不存在update的记录,是否当新数据插入,true为插入,False为不插入,默认为false
multi:可选,mongodb默认是false,只更新找到的第一条记录,如果这个参数为true,就按照条件查找出来的数据全部更新
writeConcern:可选,抛出异常的级别
需求:将lilei的年龄更新为25
示例:db.student.update({name:'lilei'},{$set:{age:25}})
累加:db.student.update({name:'lilei'},{$inc:{age:25}})
全改:db.student.update({name:'hanmeimei'},{$inc:{age:25}},{multi:true})
b、save()方法通过传入的文档替换已有的文档
语法:
db.集合名.save(
document,
{
writeConcern:<document>
}
)
参数说明:
document:文档数据
writeConcern:可选,抛出异常的级别
3.3 文档删除
说明:在执行remove()函数前,先执行find()命令来判断执行的条件是否存在是一个良好习惯
语法:
db.集合名.remove(
query,
{
justOne:<boolean>,
writeConcern:<document>
}
)
参数说明:
query:可选,删除的文档条件
justOne:可选,如果为true或1,则只删除一个文件
writeConcern:可选,抛出异常的级别
示例:db.student.remove({name:'pol'})
3.4 文档查询
a、find()方法
语法:db.集合名.find()
示例:db.student.find()
b、find()方法查询指定列
语法:
db.集合名.find(
query,
{
<key>:1
<key>:2
}
)
参数说明:
query:查询条件
key:要显示的字段,1表示显示
示例:
db.student.find({gender:0},{name:1,age:1})
db.student.find({},{name:1,age:1})
c、pretty()方法以格式化的方式来显示文档
示例:db.student.find().pretty
d、findOne()方法查询匹配结果的第一条数据
示例:db.student.findOne({gender:1})
5、查询条件操作符
作用:条件操作符用于比较两个表达式并从mongodb集合中获取数据
a、大于 $gt
语法:db.集合名.find(<key>:{$gt:<value>})
示例:db.student.find(age:{$gt:20})
b、大于等于 $gte
语法:db.集合名.find(<key>:{$gte:<value>})
c、小于 $lt
语法:db.集合名.find(<key>:{$lt:<value>})
d、小于等于 $lte
语法:db.集合名.find(<key>:{$lte:<value>})
e、大于等于 和小于等于 $gte 和 $lte
语法:db.集合名.find(<key>:{$gte:<value>},$lte:<value>})
f、等于 :
db.集合名.find(<key>:<value>)
g、使用_id进行查询
语法:db.集合名.find({"_id":ObjectId("id值")})
示例:db.student.find({"_id":ObjectId("5d05c234ea833bab0c862e2b")})
h、查询某个结果集的数据条数
db.student.find().count()
i、查询某个字段的值当中是否包含另一个值
语法:db.集合名.find({<key>:/字段内容/})
示例:db.student.find({name:/ile/})
j、查询某个字段的值是否以另一个值开头
语法:示例:db.集合名.find({<key>:/^字段内容/})
示例:db.student.find({name:/^li/})
6、条件查询and 和 or
a、AND条件
语法:db.集合名.find({条件1,条件2,……})
示例:db.student.find(gender:0,age:{$gt:16})
b、OR条件
语法:
db.集合名.find(
{
$or:[{条件1,条件2,……}]
}
)
示例:db.student.find({$or:[{age:17,age:{$gte:20}}]})
c、AND和OR联合使用
语法:
db.集合名.find(
{
条件1,
条件2,
$or:[{条件3,条件4,……}]
}
)
7、limit、skip
a、limit():读取指定数量的数据记录
db.student.find().limit(2)
b、skip():跳过指定数量的数据
db.student.find().skip(3)
c、skip和limit联合使用
通常使用这种方式来实现分页的功能
示例:db.student.find().skip(3).limit(2)
8、排序
语法:db.集合名.find().sort({<key>:1|-1})
示例:db.student.find().sort({age:1})
注意:1表示升序,-1表示降序
八. redis
1. Linux常用的redis命令
redis-server - 启动redis服务
redis-cli - 启动redis命令行客户端
save/bgsave - 手动保存数据
shutdown - 关闭服务器
quit - 退出命令行客户端
auth 密码 - 认证身份
redis-server --requirepass 密码 - 启动redis并设置密码
select 编号 - 切换数据库,默认有16个数据库,[0-15]
flushdb - 删除所在数据库的数据
flushall - 删除所有数据库的数据
info - 查看服务器的信息
2. key
2.1 查找键,参数支持正则
keys pattern
keys * --> 查看所有键
2.2 判断键是否存在
exists key
说明:如果存在返回1,不存在返回0
2.3 查看键对应的value类型
type key
2.4 删除键及对应的值
del key [key ……]
flushdb --> 删除当前数据库所有键
flushall --> 删除所有数据库的键
2.5 设置过期时间
expire key 过期时间
说明:以秒为单位
3. string
概述:string是redis最基本的类型,最大能存储512MB的数据,string类型是二进制安全的,既可以存储任何数据,比如数字、图片、序列化对象等
3.1 设置
a、设置键值
set key value --> 如果键存在,则覆盖原值,不存在则创建并赋值
setnx key value --> 如果键不存在,则创建并赋值,如果存在则不修改
b、设置键值及过期时间
setex key seconds value
set key ex value
说明:以秒为单位
c、设置多个键值
mset key value [key value……]
d、查看键超时时间
ttl key
e、替换字符串
setrange key 开始下标 新字符串
说明:从开始下标开始,将新字符串替换到原字符串
3.2 获取
a、根据键获取值
get key
说明:如果键不存在则返回None(null 0 nil)
b、根据多个键获取多个值
mget key [key……]
c、获取子串
getrange key 开始下标 结束小标
说明:获取字符串的一部分
3.3 运算
a、将key对应的值加1
incr key
b、将key对应的值减1
decr key
c、将key对应的值加整数
incrby key 数字
d、将key对应的值减整数
decrby key 数字
3.4 删除
a、删除指定键
del key
b、删除所有键
flushdb
c、删除所有数据库的内容
flushall
3.5 其他
a、追加值
append key value
b、获取键值长度
strlen key
c、获取值后赋值
getset key value --> 获取旧值并返回,然后用value替换旧值
4. hash
概述:hash主要用于储存对象
{
name:'tom',
age:18
}
4.1 设置
a、设置单个值
hset key field value
b、设置多个值
mhset key field value [field value……]
4.2 获取
a、获取一个属性的值
hget key field
b、获取多个属性的值
hmget key field [field……]
c、获取所有属性和值
hgetall key
d、获取所有属性
hkeys key
e、获取所有值
hvals key
f、返回包含数据的个数
hlen key
4.3 其他
a、判断属性是否存在
hexists key field
说明:存在返回1,不存在返回0
b、删除属性及值
hdel key field [field ……]
c、返回值的字符串长度
hstrlen key field
5. list
概述:列表的元素类型为string,按照插入顺序排序,在列表的头部或尾部添加元素
5.1 设置
a、在头部插入
lpush key value1 [value2 ……]
说明:value2的值在value1前面
b、在尾部插入
rpush key value [value ……]
c、在参考元素的前|后插入新元素
linsert key before|after 参考元素 value
d、设置指定索引的元素值
lindex key 索引值
注意:索引值从0开始
注意:索引值可以是负数,表示偏移量是从list的尾部开始,如-1表示最后一个元素
5.2 获取
a、移除并返回key对应的list的第一个元素
lpop key
b、移除并返回key对应的list的最后一个元素
rpop key
c、返回存储在key的列表中的指定范围的元素
lrange key start end
注意:start end都是从零来数
注意:偏移量可以是负数
d、移除并返回key对应的list的第一个元素,如果不存在则阻塞在此等候
blpop key
e、移除并返回key对应的list的最后一个元素,如果不存在则阻塞在此等候
brpop key
5.3 其他
a、裁剪列表,改为原集合的一个子集
ltrim key start end
注意:start end都是从零来数
注意:偏移量可以是负数
b、返回存储在key里的list的长度
llen key
c、返回列表中索引对应的值
lindex key index
d、删除指定个数值为value的元素
lrem key 个数 value
6. set
概述:无序集合,元素类型为string类型,元素具有唯一性,不重复
6.1 设置
a、添加元素
sadd key member [member……]
6.2 获取
a、返回key集合中所有的元素
smembers key
b、返回集合元素个数
scard key
6.3 运算
a、求多个集合的交集
sinter key [key……]
b、求多个集合的差集
sdiff key [key……]
c、求多个集合的合集
sunion key [key……]
d、判断元素是否在集合中,存在返回1,不存在返回0
sismember key member
6.4 删除
a、删除指定的元素
srem key member
b、随机取出指定个数个元素
spop key 个数
7. zset
概述:
a、有序集合,元素类型为string,元素具有唯一性,不能重复
b、每个元素都会关联一个double类型的score(表示权重),通过权重的大小排序,元素的score可以相同
7.1 添加
格式:zadd key score member [score member……]
示例:zadd zi 1 a 2 b 3 c 4 d
说明:注意:值在前,元素在后
7.2 获取
a、返回指定范围的元素
zrange key start end --> 升序排序
zrevrange key start end --> 降序排序
b、返回元素个数
zcard key
c、返回有序集合key中,score在min和max之间的元素
zcount key min max
d、查看score在min和max之间的排行
zrangebyscore key min max
e、返回有序集合key中,成员member的score的值
zscore key member
f、查看元素的排名
zrank key member --> 升序查看元素的排名
zrevrank key member --> 降序查看元素的排名
7.3 删除
zrem key member --> 删除指定的元素
7.4 计算
zincrby key member 数值 --> 给指定元素的值加上提供的值
8. geo地理位置
8.1 添加
geoadd 集合名 经度 纬度 位置备注 [经度 纬度 位置备注...]
8.2 计算
geodist 集合名 位置备注1 位置备注2 [km]
说明:查看两个位置的距离,后面添加km表示显示单位为千米
georadius 集合名 经度 纬度 距离 [单位] [withdist]
说明:查看集合中距离指定经纬度指定范围的位置点,withdist表示显示距离
9. 事务
mult - 开启事务
exec - 执行(提交)
discard - 放弃(回滚)
watch - 监控数据,如果被其他程序改变,则提交失败
10. 主从复制
redis-server --slaveof IP地址 端口 - 设置启动的redis是哪个redis的从机
info replication - 查看redis主从状态
九. postgresql
1. 安装
sudo apt-get install postgresql - ubuntu安装方法
安装后会自动创建一个postgres用户,该用户拥有postgresql的最高管理权限,需要切换到该用户下才能进行后续操作
2. 命令行操作
psql --version - 查看版本
psql -l - 列出所有数据库
createdb 数据库名 - 创建数据库
psql 数据库名 - 进入该数据库
dropdb 数据库名 - 删除数据库
createuser 用户名 - 创建用户
dropuser 用户名 - 删除用户
3. 数据库命令
``
十. 阿里云操作
1.连接云服务器(git bash)
ssh root@ip地址
输入密码
注意:更改密码后需要重启
退出登录:logout
2.更改连接超时
vim /etc/ssh/sshd_config中
\#ClientAliveInterval 0
\#ClientAliveCountMax 3
修改为:
ClientAliveInterval 30
ClientAliveCountMax 86400
客户端每隔多少秒向服务发送一个心跳数据
客户端多少秒没有相应,服务器自动断掉连接
重启sshd服务(centos7+)
systemctl restart sshd
3.做免密方法
在本地进入~/.ssh目录
在git bash中使用命令ssh-keygen生成公钥和私钥
.pub就是公钥
在Linux中的公钥放置位置:~/.ssh/authorized_keys文件中
十一. 网络安全
SQL注入攻击:用字符串拼接的方式未对用户输入进行验证导致将用户输入内容部分作为代码执行
XSS跨站脚本攻击:对用户输入未检测或者转义不足导致用户输入部分代码作为命令进行了执行
点击劫持攻击:在网页上防治一个透明的iframe,展示给用户不一样的内容诱导用户点击iframe上的内容。
十二. Docker
1. 安装
yum install -y docker - centos安装docker
systemctl start docker - 启动docker
windows下更改国内镜像在右下角图标右键settings>Docker Engine中添加以下代码
Linux下更改国内镜像在/etc/docker/daemon.json中添加以下代码
{
"registry-mirrors": [
"http://hub-mirror.c.163.com",
"https://registry.docker-cn.com"
]
}
重新安装docker-ce方法
- 查看内核版本(centos7 64位要求3.10+,centos6 64位要求2.6+)
uname -r
- 更新底层库文件
yum update
- 移除可能存在的旧版docker
yum erase -y docker docker-common docker-engine
注意: 移除前先删除容器和镜像
- 安装工具包和依赖项
yum install -y yum-utils device-mapper-persistent-data lvm2
- 通过yum工具包添加docker-ce源
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
- yum安装并启动docker
yum -y install docker-ce
systemctl start docker
2. 命令
docker version - 查看docker版本
docker info - 查看详细信息
docker pull 镜像名 - 下载镜像
docker images - 查看所有本地的镜像
docker rmi 镜像id - 删除镜像
docker run -d -p 80:80 --name mynginx --rm nginx:latest - 创建并运行容器,
-d - 后台运行
-p port1:port2 - 指定端口 外部端口:内部端口
-v/--volume 外部文件夹:内部文件夹 - 数据卷操作,将外部文件夹映射到容器内部文件夹
--link 容器名:自定义网络别名 - 给容器网络设置别名
--name 容器名字 - 给创建的容器命名
--rm - 为停止容器的时候容器自动删除
镜像名:版本号 - 指定镜像和版本,latest为最新版本,默认不写也为最新版本
docker ps - 查看docker的端口占用
docker start mynginx - 运行已经创建的容器
docker stop mynginx - 停止正在运行的容器
docker container ls -a - 查看所有的容器,不加-a表示正在运行的容器
docker rm mynginx/ docker rm -f mynginx - 删除容器
docker container prune - 清空所有容器
docker exec -i -t mynginx /bin/bash - 进入容器的交互环境并启动bash
docker cp - 容器内外拷贝文件
docker inspect --format '{{ .NetworkSettings.IPAddress }}' 容器id - 查看容器IP地址
docker commit 容器id 自定义镜像名字 - 将容器打包成镜像
docker save 镜像名 -o 文件名 - 镜像保存为文件
docker load < 文件名 - 加载镜像
docker login - 登录docker hub
docker push - 将自己的镜像上传到docker hub
3. dockerfile构建镜像
3. 常见容器创建
docker run -d -p 6379:6379 --name redis-master redis:latest redis-server --requirepass 1qaz2wsx - 创建redis主机
docker run -d -p 6380:6379 --link redis-master:redis-master --name redis-slave-1 redis:latest redis-server --slaveof redis-master 6379 --masterauth 1qaz2wsx - 创建redis从机
docker run -d -p 3306:3306 -v /root/docker/mysql/conf:/etc/mysql/mysql.conf.d -v /root/docker/mysql/data:/var/lib/mysql --name mysql57 -e "MYSQL_ROOT_PASSWORD=123456" mysql:5.7.29 - 创建mysql容器并将数据备份